VAEs are a specific form of autoencoders. However, they differ in that they are probabilistic models that encode latent variables of training data as a probability distribution, not a singular output. They are generative models, because they are probabilistic: we sample latent vectors from the distribution and decode it for output. The name variational comes from Variational Inference.
VAE Scenario
Our vanilla autoencoders are purely for learning a useful latent representation - but we have no way of sampling useful \(z\) latent vectors for proper generation. Hence VAEs solve the problem by conditioning our autoencoders to learn continuous and structured latent spaces, giving as an actual tool for image generation tasks!
By continuous, we mean small perturbations in latent space should generate a small change in decoder output. Structure means different vectors in latent space can give us semantic meaning!

VAE Overview
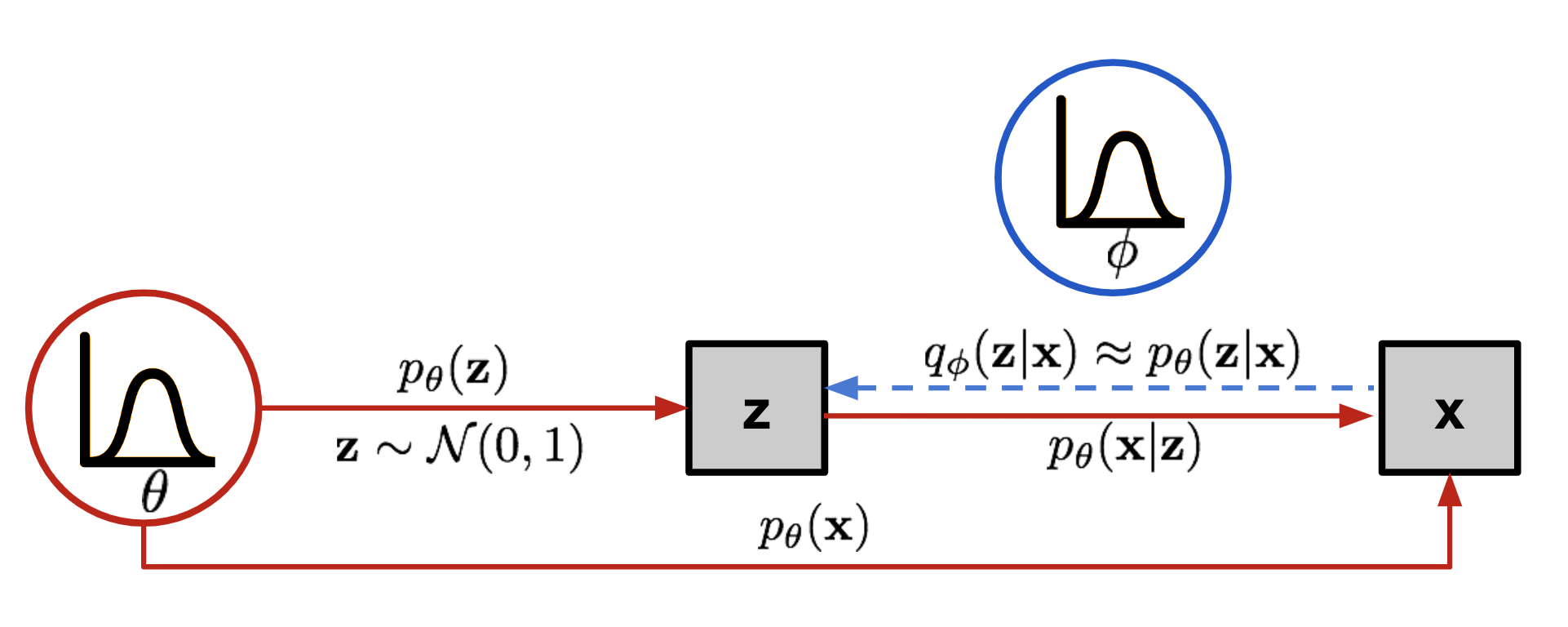
Let \(\theta\) define the parameters of our VAE model. Then we describe the relations between our input data \(x\) and latent vector \(z\) as
- our prior \(p(z)\) defines a known distribution for sampling latent vectors, to which then we can pass through our decoder for image generation
- our true likelihood \(p_{\theta}(x \mid z)\) which is our decoder! For a specific image \(x^i\), there is a specific region of \(z\) in our prior distribution that has high probability of reconstructing \(x^i\) with our decoder: this is what contributes to the integral for \(p_\theta(x) = \int p_\theta(x\mid z)\,p(z)\,dz\) - where \(p_{\theta}(x \mid z)\) has the most mass and \(p(z)\) is large. Remember that during inference for actual random generation, we randomly sample from \(p(z)\) and pass it through our decoder \(p_{\theta}(x \mid z)\) for a new random image. Encoder is not needed there.
- our true posterior \(p_{\theta}(z \mid x)\) By Baye’s Rule, \(p_\theta(z\mid x) = \frac{p_\theta(x\mid z)\,p(z)}{p_\theta(x)}.\) This ends up being intractable, and must be approximated, through network parameterized by \(\phi\) instead!
- our approximate posterior \(q_{\phi}(z \mid x)\) which is our encoder! We need a good encoder \(q_{\phi}(z\mid x)\) that generates a region of \(z \sim q_{\phi}(z\mid x)\) (and later which decodes to good enough \(x\)).
- our marginalized likelihood \(p_{\theta}(x)\) or evidence of observing \(x\) under our VAE model! \(p_\theta(x) = \int p_\theta(x\mid z)\,p(z)\,dz\) We need this for our likelihood function and determining loss.
Encoder
In order to sample our latent variable \(z \sim \mathbb{R}^J\), we define it as sampling from a prior distribution we know such as the Gaussian distribution
Because our posterior for the latent (inference) is intractable
then we approximate using variational inference, using our approximate posterior encoder \(q_{\phi}(z \mid x)\) which outputs \(\mu_{\phi}(x)\) and \(\sigma_{\phi}^2(x)\) in order to describe a gaussian distribution. Note that our variational family need not be gaussian!, but we like for it to be because of easy parametrization and simplicity reasons.
Reparameterization Trick
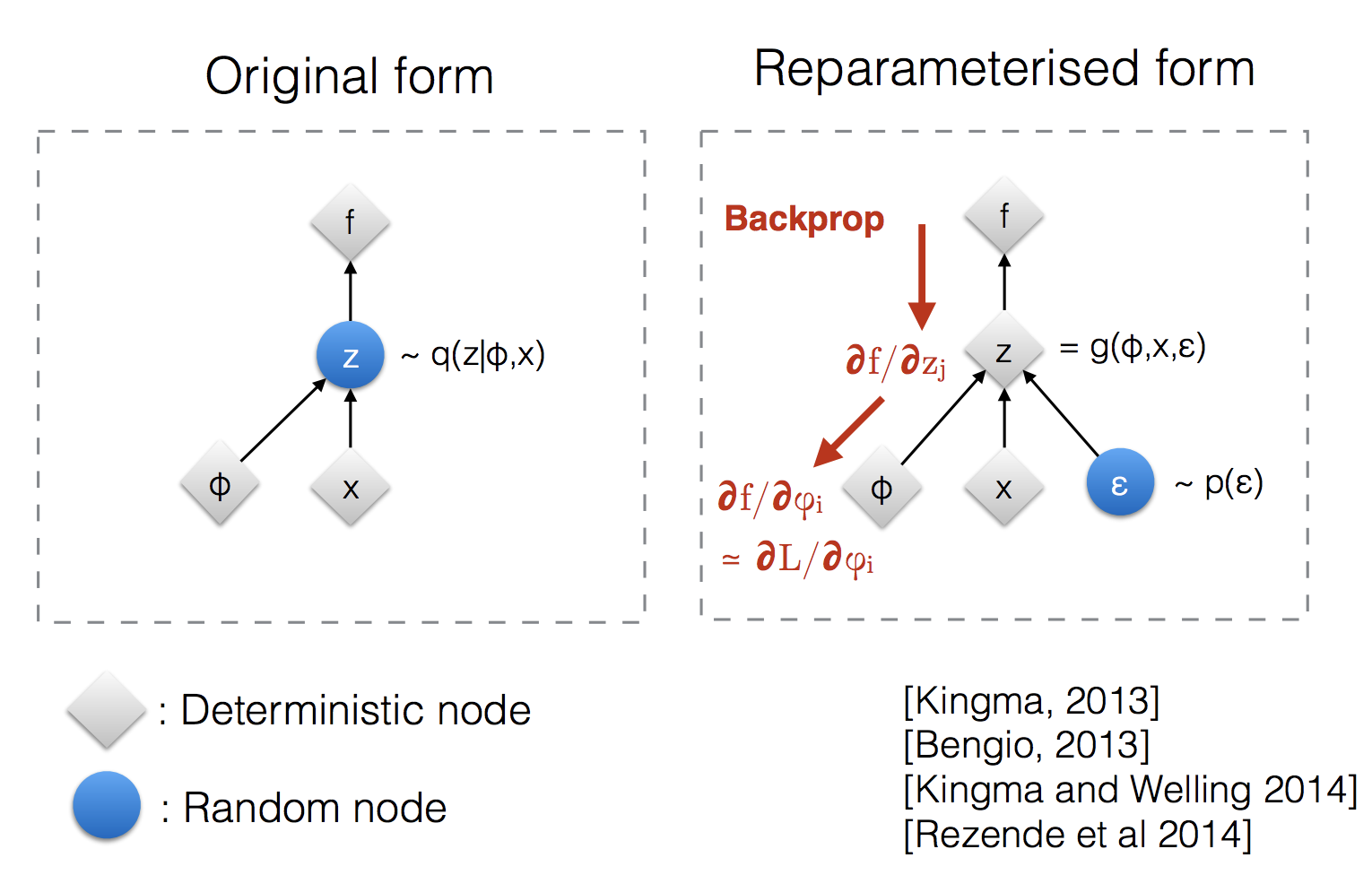
Instead of sampling \(z\) from \(q_\phi(z\mid x)\) directly, in order for gradients to actually flow from \(z\), then we must reparameterize \(z\) as
Now the computation of \(z\) is deterministic, with the randomness is offloaded to \(\epsilon\)
In our computation graph, we see that the computation graph is back propagable!
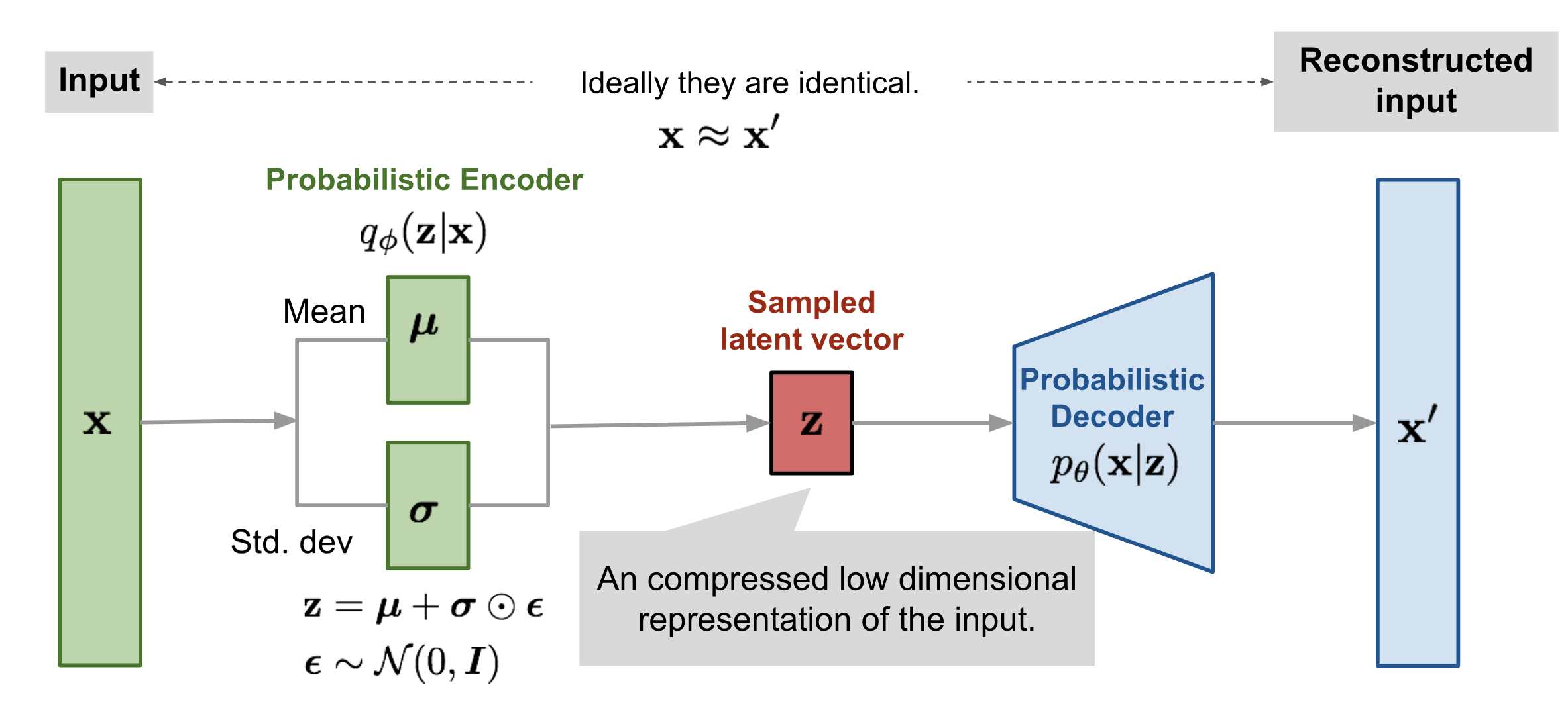
Decoder
We also can model the decoder \(p_{\theta}(x \mid z)\) for generation as a gaussian (for real-valued data vs binary? !REVIEW)
where \(f_{\theta}(z)\) is our deterministic neural net part of the decoder. Again for sampling we also need to use the reparameterization trick as discussed before.
Loss Function - VAE Training Objective
This is the most important and complex part in understanding VAEs!
MLE
For a review of MLE, remember the goal in MLE is to find the optimal \(\theta^*\) such that \(p_{\theta}(x \mid z),\ p_{\theta}(z)\) best explain our dataset \(X=\{x^{(i)}\}_{i=0}^N\) using the likelihood estimation of our marginalized likelihood \(p_{\theta}(x)\) for all training samples in our VAE.
or more simply log likelihood.
But remember, that this inner term is something intractable.
But this is where the magic of ELBO comes in
Deriving the ELBO, Evidence Lower Bound
By evidence, we can derive the log likelihood of a function given fixed parameters \(\theta\). The derivation is a bit tricky, 1. we need to introduce an expectation somehow to introduce KL divergence terms 2. the identity multiplication in the log term is needed to give us tractable terms; using Jensen’s Inequality there are other derivations that turn out simpler. Since the term is intractable, we do some manipulation
For a single sample \(x\), then this resolves to
The last component \(D_{KL} \left[ q_{\phi}(\mathbf{z}|\mathbf{x}) \parallel p(\mathbf{z}|\mathbf{x}) \right]\) measures the difference between our encoder estimate’s posterior and our real posterior (the basis of Variational Inference, since we don’t know what the real posterior is!) and is importantly not tractable. So it is important to realize the ELBO is only a lower bound, so we are not necessary always optimizing the log-likelihood. But generally, because this is the gap between the true log likelihood and our ELBO estimate, minimizing this term is beneficial for accurate estimates!
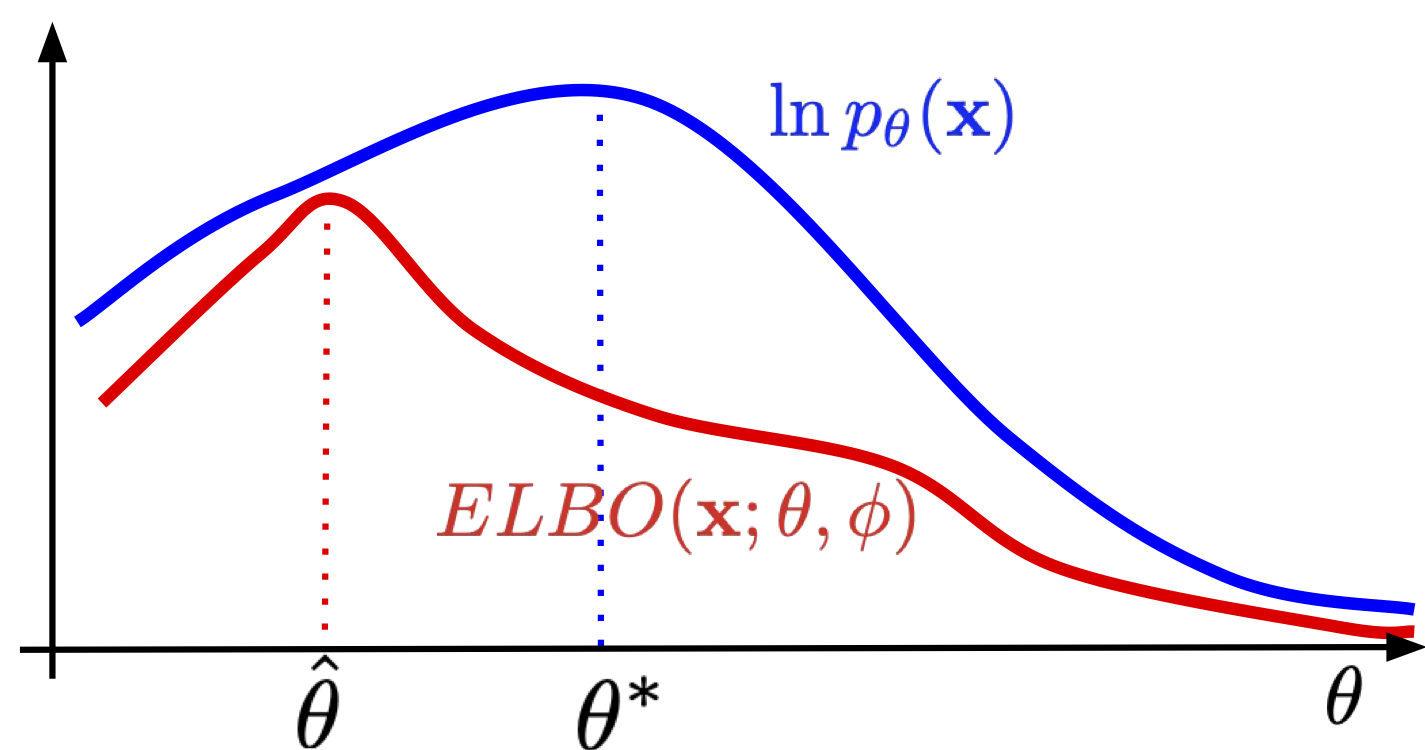
Taking a closer look at what maximizing the ELBO means (conventionally, this loss expression should be negated, but lets think about maximizing loss/ELBO for clarity).
- Reconstruction loss in order to generate likely samples \(x^i\). For each \(z\) drawn from the encoder’s approximate posterior, how likely can we generate that sample \(x^i\)?
- Regularization term in order to push the encoder (approximate posterior) to match our gaussian prior.
We encourage the approximate posteriors to fit in a large gaussian, so that \(\mu_\phi(x)\) is somewhat near the origin.
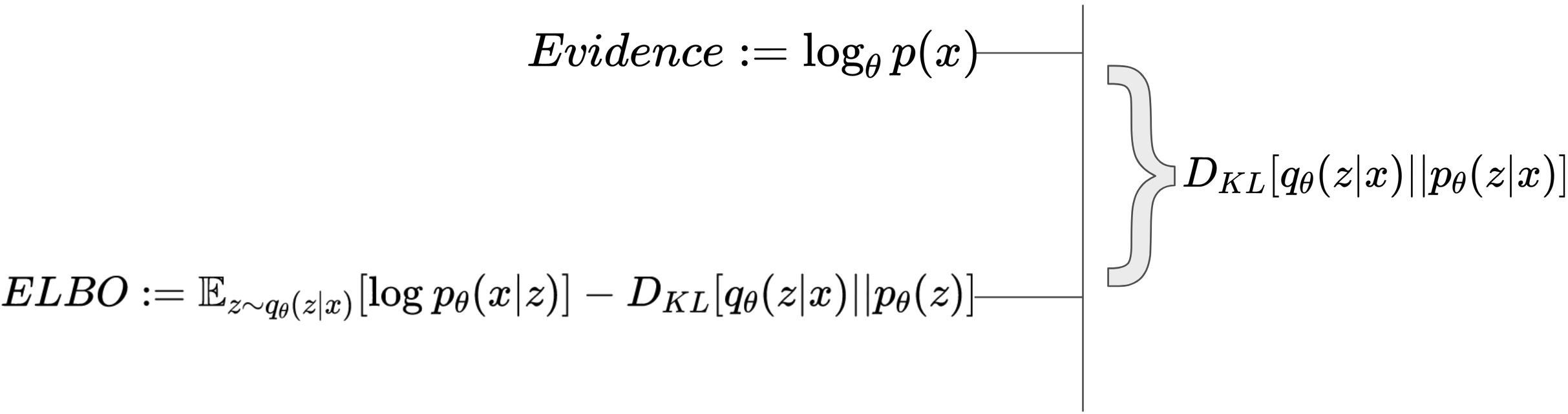
Illustration of ELBO term and regularization
Note then we prevent “spikes” from forming (low variance posteriors)
As for actually computing the terms
- This requires drawing \(K\) samples of \(z\).
For the log term also being Gaussian, this is actually equivalent to MSE loss or minimizing \(\|x^{(i)} - f_\theta(z)\|^2,\) 2. Since we have a closed form analytical expression as above, then all we need to do is for each sample \(x^{(i)}\) run it through the encoder and calculate the KL loss for that sample.
Log-Likelihood
So we aim to minimize negative log-likelihood which we can do using our empirical average.
Sources
The best blogs I’ve read - many of these require higher degree of mathematical maturity or a depth that may not be necessary for what I need