Unliked value-based methods, policy optimization methods search over policy parameters without computing structured value representations for states (or state-action pairs), in order to find parameters that maximize (or minimize) a policy objective function.
Let \(U(\theta)\) be any policy objective function. Then the general structure would follow something like
- Initialize policy parameters \(\theta\)
- Sample trajectories \(\tau_{i} = \{ s_{t}^i, a_{t}^i \}_{t=0}^T\) by deploying the current policy \(\pi_{\theta}(a_{t}\mid s_{t})\)
- Compute gradient vector \(\nabla_{\theta} U(\theta)\) Typically this is done through estimation from collected data.
- Apply a gradient ascent update \(\theta \leftarrow + \alpha \nabla _\theta U(\theta)\)
In comparison to value-based methods, policy-based methods are
-
more effective in high-dimensional + continuous action spaces Value-based methods should generally select optimal actions based on something like \(\arg \max_{a} Q(s,a)\) that faces problems across high dimensions.
-
better at learning stochastic policies Policy-based methods are naturally stochastic: this is because our policy parameters \(\theta\) parameterize a distribution that our actions are sampled from. Remember that value-based methods need to rely on heuristics like epsilon-greedy to embed exploration in their policies.
Why is stochasticity a good thing?
- exploration is optimal to train any policy
- in partial-observability settings/environments, deterministic mappings aren’t the only optimal solution
Evolutionary Methods for Policy Search
These are called evolutionary methods because they closely follow the evolution of a population!
- Initialize a population of parameter vectors Genotypes
- Make random permutations to each parameter vector Simulate mutations in offspring
- Evaluate the perturbed parameter vector
- Update your policy parameters to move to favor the best performing parameter vectors Survival of the fittest enabling fitness in this offspring
These are examples of black-box policy optimization, where we treat the policy and environment as a “black box” that we can query (run rollouts) and update our policy based purely on performance we can observe;
- we do not learned a structured “state” representation of state values and/or state-action values based on the structure of Bellman equations
- use gradients to update policy parameters directly like in policy gradient methods, but may do so indirectly like in NES
CEM: Cross-Entropy Method
In this method, we
- sample \(n\) policy parameters \(\theta_{i}\) from a multivariate Gaussian distribution matrix \(p_{\phi}(\theta)\)
- Evaluate those \(n\) parameters to generate a reward signal or scalar return \(F(\theta_{i})\)
- select a proportion \(\rho\) of those parameters with highest score as our elite samples
- use their corresponding \(\mu\) and \(\sigma^2\) to update our reference matrix for sampling, which basically means setting the new mean as the mean of those highest \(\rho n\) parameters and setting the new variance as simply the variance of those selected elite samples!
This worked really well up to the 2010’s and in low dimensional search space dimensions, shown to work well in Tetris (Szita, 2006), where we can craft a state-value function that is a linear combination of 22 basis functions \(\phi(s)\) (individual column heights, height differences, etc)
These evolutionary search methods weren’t a threat to DQN implementations at the time because they couldn’t scale to large non-linear neural nets with thousands of parameters.
CMA-ES: Covariance Matrix Adaptation
Instead of limiting ourselves to diagonal Gaussian, we search by learning a full covariance matrix so instead of just updating the mean and variances, we’re updating the full covariance matrix.
Visually, if there is an objective function we are trying to reach that is best maximized with samples in a 2d rotated ellipse, then we should utilize all the entries in a full covariance matrix which then allows us to rotate a standard diagonal gaussian matrix (x-y aligned ellipse) to best maximize this objective function efficiently.
NES - Natural Evolutionary Strategies
NES considers every offspring when updating our policy parameters - they optimize our expected fitness objective by updating the parameters of our search distribution through a natural gradient, specifically updating our learned mean \(\mu\), while fixing our covariance this time.
Consider the parameters of our policy \(\theta \in \mathbb{R}^d\) are sampled from a Gaussian distribution with learned mean \(\mu \in \mathbb{R}^d\) and fixed diagonal covariance matrix \(\sigma^2I\) (which is not being learned). We denote this distribution as \(P_{\mu}(\theta)\)
Our goal is find the best possible policy distribution, parameterized by \(\mu\), that our policy is sampled from (through \(\theta\))
based on a fitness score which is the expectation of reward over entire trajectories
Deriving the Natural Gradient
Computing the update for our mean \(\mu\) through this objective is as follows:
From this derivation, we have shown that this gradient can be estimated by
- sampling \(N\) parameters \(\theta_{i}\), running trajectories for each parameter, and obtaining our scalar fitness score \(F(\theta_{i})\) for each sample
- Then we simply need to scale by a sampled noise term \(\epsilon\) divided by our variance \(\sigma\) and average out all scaled terms!
To expand on that last step, in order to back propagate through Gaussian distributions to \(\mu\), then the sampling of \(\theta_{i} \sim \mathcal{N}(\mu, \sigma^2 I)\) needs to be converted through the reparameterization trick so that \(\theta_{i} = \mu + \sigma \epsilon_{i},\ \epsilon_{i} \sim \mathcal{N}(0, I)\).
Based on this derivation we can now apply gradient ascent to iteratively update our \(\mu\)! (based on learning rate \(\alpha\))
Black-Box Optimization
To clarify, this is still black-box optimization:
- We do not need to know anything about how we are computing our fitness score, we are simply using raw output returns given our samples \(\theta_{i}\)
- We are not computing computing analytic gradients of \(F(\theta)\) wrt to \(\theta\) in order to update our policy parameters directly; in fact, we compute gradients wrt to a different, known object that we have set: the search distribution \(P_{\mu}(\theta)\)
Scalability + Parallelization of ES
The reason why this scales well for large dimension \(\theta\) when we are working with large neural networks is that when parallelizing this natural gradient computation across multiple worker processes, then each worker needs to compute this term \(\epsilon_{i} F_{i}(\theta_{i})\). This means we need to distribute back and forth this large \(\theta_{i} = \mu_{t} + \sigma \epsilon_{i}\) vector across all our \(n\) workers and can do so through
- Coordinator broadcasts \(\mu_{t}\) once per update step to all workers
- Coordinator sends \(\epsilon_{i}\) to all \(n\) workers individually, which allows every worker to compute \(\theta_{i}\)
- Each workers runs trajectories and sends back \(F(\theta_{i})\) to the central workers.
Because of reparameterization only this \(\epsilon_{i}\) needs to be sent back and forth, but this is still a very large parameter, so instead we use a pseudo random number generator to compute \(n\) (tiny) seeds and then send these small seeds to the \(n\) workers, which can they reconstruct each large dimension \(\epsilon_{i}\) and compute our returns \(F(\theta_{i})\) which is just a scalar! So communication time is cut a lot.
Local Maxima Issue
In order to prevent ES methods from getting stuck in local optima, we average our search over multiple tasks and related environments to improve robustness and our objective can become more more generalizable.
Policy Gradient
We no longer consider black-box optimization methods. Instead of updating a search distribution that our policy parameters are sampled from, we directly update our policy parameters, because we need to compute analytic gradients directly!
Policy Objective
One reasonable policy objective is to maximize our expected trajectory reward over distribution of all trajectories parametrized by our policy parameters \(\theta\) (assuming a discrete trajectory space).
Remember that \(P_{\theta}(\tau)\) is the probability distribution over seeing that entire trajectory when we run \(\pi_{\theta}\) in our environment which abstracts three key ingredients
- the initial state being sampled from an initial state distribution
- the stochasticity of the policy in which actions are sampled from - this is what our \(\theta\) actually parameterizes.
- the dynamics of the environment resulting in stochastic next states \(s_{t+1}\)
It’s assumed that \(P\) is a probability density function that is continuous and differentiable - necessary to propagate our gradient as we will see in the derivation.
We now need to figure out how to compute this gradient in order to find optimal \(\theta\):
Finite-Difference Methods
One way to try and approximate policy gradient of \(\pi_{\theta}(s)\) by nudging \(\theta\) in every possible small amount dimension and approximate partial derivatives as such:
This was used to train these AIBO robots to walk. But this is really not feasible in high dimensions
Derivatives of the Policy Objective
Policy gradients aim to exploit our factorization of \(P_{\theta}(\tau) = \prod_{t=0}^H P(s_{t+1} \mid s_{t}, a_{t}) \pi_{\theta}(a_{t} \mid s_{t})\) to compute approximate gradient estimate for
In comparison to evolutionary methods, here the challenge is to compute derivatives w.r.t variables that parameterize a distribution that our expectation is summed over. The derivation uses the same log probability trick as derived for evolutionary methods; also we assume discrete trajectory space to sum over - if continuous, the derivation is largely the same but the justification for moving gradients inside the integral terms is different and above my math knowledge.
I think this part is intuitively explainable, our policy objective gradient is equivalent to increasing the log probability of trajectories that give a positive reward and decreasing the log probability of trajectories that give a negative reward.
The key observation is that this expectation can be simplified much further because our trajectories do encapsulate the dynamics of the environment - but this is not specifically parametrized by our policy parameters, so the derivatives of our trajectories propagate to derivatives of taking actions under our policy.
Then completing our derivation
To approximate the gradient, we use an empirical estimate to from \(N\) sampled trajectories!
Computing Policy Gradient
And the natural question is whether the derivative term is computable - which yes it is.
- If our action space is continuous, then we our policy network can be gaussian, outputting a mean and standard deviation.
- If our action space is discrete, obviously we apply a final softmax layer to output a discrete probability distribution over finite action space. Then for stochasticity, we can query a categorial distribution based on these probabilities for sampling.
Temporal Structures
Can we do better than a standard \(R(\tau)\) of the entire trajectory for every gradient update? One problem is the issue with scalar \(R(\tau)\), why should the action an agent takes at time step \(t\) be scaled by the reward trajectory of time steps that occurred before that \([0, t-1]\)?
Instead, we should emphasize causality: Only future rewards should be attributed to the action taken at timestep \(t\)
REINFORCE - Monte Carlo Policy Gradient
The above discussion concludes REINFORCE - the simplest policy gradient also referred to as “vanilla” policy gradient.
- Initialize policy parameters \(\theta\)
- Sample trajectories \(\{\tau_{i} = \{s_{t}^i, a_{t}^i \}_{t=0}^T\}\) by deploying the current policy \(\pi_{\theta}(a_{t} \mid s_{t})\)
- Compute gradient vector \(\nabla_{\theta} U(\theta) \approx \hat{g} = \frac{1}{N}\sum_{i=1}^N \sum_{t=1}^T \nabla_{\theta} \log \pi_{\theta}(a_{t}^{(i)} | s_{t}^{(i)}) G_{t}^{(i)}\)
- Perform Gradient Ascent: \(\theta \leftarrow \theta + \alpha \nabla_{\theta}U(\theta)\)
Baselines with Advantages
Our gradient estimator is unbiased, but still can have high variance
One issue with weighting our gradient updates with \(G_{t}\) is the following situation:
- a state \(s_1\) has all actions averaging out to a high positive magnitude reward of \(4000\)
- a state \(s_{2}\) has all actions averaging out to a negative reward of \(-4000\) Then no matter if we take a very bad action at \(s_1\) versus a very good action at state \(s_2\) the state’s baseline level of reward (expectation) is the major scaling factor in our gradient update, not the intention of whether we took a good or bad action in the first place.
To counteract this we should then only consider the trajectory reward above our a constant-term baseline - Advantages - at that state!
Actually, this new \(\hat{g}'\) is still equal to our original \(\hat{g}\) because in expectation the baseline term has zero expectation.
And our subtraction of baseline to consider relative reward has effectively reduce the scale of gradient updates quite a bit, thus we minimize variance overall!
Baseline Choices
- Constant Baselines using the average return of the policy \(b = \mathbb{E}[R(\tau)]\)
- Time-dependent Baselines \(b_{t} = \sum_{i=1}^N G_{t}^{(i)}\) where we average temporal reward over all trajectories
- State-dependent Baselines i.e. value function \(b(s_{t}) = V_{\pi}(s)\)
Actor-Critic Methods
Actor-Critic methods build of our state-dependent baselines used in REINFORCE with baselines method where our action advantage is \(A^\pi (s_{t}^i, a_{t}^i) = G_{t}^{(i)} - V_{\phi}^\pi(s_{t}^i)\). But the \(G_{t}^{(i)}\) term can have high variance: it’s a single rollout Monte-Carlo return based on our \(s_{t}\) and \(a_{t}\) and varies from our environment; but doesn’t this sound familiar?
Our returns \(G_{t} = \sum_{k=t}^T R(s_{k}, a_{k})\) are exactly estimated by our Q-functions \(Q^\pi(s,a) = \mathbb{E}[G_{t} \mid s_{t}, a_{t}]\) by definition. Furthermore, however, if our critic function only estimates our value functions \(V_{\phi}^\pi(s)\) already, then we should expand our bellman equations to express Q-functions in terms of value functions: \(Q^\pi(s,a) = \mathbb{E}[G_{t} \mid s_{t}, a_{t}] = \mathbb{E}[R_{t} + \gamma G_{t+1} \mid s_{t}, a_{t}] = \mathbb{E}[R_{t}+V(s_{t+1}) \mid s_{t},a_{t}]\).
Then our action advantages can be simplified as
- Initialize actor policy parameters \(\theta\) and critic parameters \(\phi\)
- Sample trajectories \(\{\tau_{i} = \{s_{t}^i , a_{t}^i\}_{i=0}^T \}\) by deploying our current policy \(\pi_{\theta}(a_{t} \mid s_{t})\)
- Calculate value functions \(V_{\phi}^\pi(s)\) through MC or TD estimation
- Compute action advantages \(A^\pi (s_{t}^i, a_{t}^i) = G_{t}^{(i)} - V_{\phi}^\pi(s_{t}^i)\)
- \(\nabla_{\theta}U(\theta) \approx \frac{1}{N}\sum_{i=1}^N \sum_{t=0}^T\log \pi_{\theta}(a_{t} \mid s_{t}) A(s_{t}, a_{t})\)
- \(\theta \leftarrow \theta + \alpha \nabla_{\theta}U(\theta)\)
In some sense the actor-critic is just “policy iteration” written in gradient form.
- We run the policy and collect a series of \(N\) trajectories.
- Based on the performance, we compute advantages for each time step during each trajectory
- Then we update our policy parameters directly using a policy gradient that is computed through these advantages.
A2C - Advantage Actor-Critic
The trajectories we collect arrive sequentially, while stability of training our policy networks require the gradient updates to be decorrelated - a problem we fixed in Q-learning using replay buffers - a solution is A3C by parallelizing the experience collection to multiple agents in order to stabilize training.
Workers run in parallel, computing gradients from their own rollouts, but we batch updates after each worker has finished their process to a combined gradient update step - ensuring consistent /stable gradient updates.
A3C - Asynchronous Advantage Actor-Critic
The natural performance optimization to make is what if the workers worked asynchronously and computed + provided gradient updates without waiting for all workers each iteration.
PPO - Proximal Policy Optimization
PPO is derived from policy improvement logic and more so a approximate policy iteration method than a policy gradient method.
High UTD
Obviously it seems to us that a high UTD is efficient with collected data - and a bottleneck in RL for complex environments is exactly data collection - so we want to come up with methods that work well with high UTD.
Here’s the issue:
if we apply one gradient update step, then we land on a new policy \(\pi'\) parameterized by \(\theta'\). We cannot compute the same policy gradient estimate for \(\nabla_{\theta}U(\theta)\) by reusing the past rollouts (in order to compute the advantages).
This means that forcing a high UTD is a noisy estimate based on limited experience and can result in policy drifts. This is a motivator for PPO and TRPO methods as we discuss, which aim to fix this issue through
Policy Improvement
Performance of Policy
If we quantify the performance of a policy as expected return over all trajectory
and define a discounted state visitation distribution that weights time spent in a specific state \(s\) over all trajectories given a policy \(\pi\)
where
- \(\Pr_{\pi}\) specifically refers to probability over policy (all policy-induced randomness)
- the sum of all pmfs for \(d^\pi(s)\) over all states \(\sum_{s} d^\pi(s) = \frac{1}{1-\gamma}\)
- the discounted average of some state-dependent function \(f(s)\) over trajectories is equal to the average over state weighted by how often we visit them
Performance Difference Lemma
Then we can show that the policy improvement from \(\pi \rightarrow \pi'\) can be written as expected advantage over state visitation distribution and action sampling from our policy.
Policy Improvement Formulation
We aim to find the maximum new policy \(\pi'\) which corresponds to an expression
Importance Sampling
But our whole goal for performance is to not sample from \(\pi'\) for the \(s,a\). If we can’t sample from \(\pi'\) (we can but the whole goal is to avoid sampling) of a distribution \(p(z)\), but want to compute an expectation of a function \(f(z)\) under that distribution, then importance sampling allows us to sample from a different easier proposal/behavior distribution \(q(z)\) then scale using a term called important weight our function values computed from those samples through manipulation:
which works as long as the denominator isn’t \(0\) whenever \(p(z)\) is nonzero.
Derivation
Then to apply this trick to our formulation, we aim to express our expectation entirely in terms of \(\pi\), our first attempt in re-expressing our state visitation distribution in terms of \(\pi\) would be
but calculating state-visitation ratio \(\frac{d^{\pi'}(s)}{d^\pi(s)}\) is hard in itself - because the discounted visitation for \(\pi'\) is unknown - and if we try to estimate this ratio with a large amount of sampling, then because this is a high variance term that could explode in certain states leading to instability in the computation.
PPO fixes this by simply keeping \(\pi\) close to \(\pi'\) so that the state-visitation distribution naturally induces an approximate equality of \(d^{\pi'}\approx d^\pi\). And we apply the same importance sampling trick for \(\pi'(\cdot\mid s_{t})\) which note the ration \(\frac{\pi'(\cdot\mid s_{t})}{\pi(\cdot\mid s_{t})}\) is easy to deal with - this is computable from our policy network in a single forward pass!
Now, to compute this objective max function, we need to take gradient ascent steps wrt to this object, and rewrite in the same policy gradient form
But we still have this issue of need to have a high UTD and resulting in policy drift. PPO aims to enforce some closeness penalty constraints on how far the new policy \(\pi'\) can drift from \(\pi\) on each gradient update! This is a regularization term.
Clipped Ratio Objectives
What PPO does is use a soft approximation by utilizing ratio clipping keeping the \(\frac{\pi'(a\mid s)}{\pi(a \mid s)}\) close to 1 instead of using an explicit distance metric (KL Divergence) like with TRPO. Remember the whole purpose is to make sure the old batch is representative of the new policy so we can get high UTD.
This can be expressed as
Note that a naive clip objectives clips our ratio on both sides of the curve. But this has the issue of
- if our advantage \(A > 0\) and our ratio \(r < 1 - \epsilon\) because the clipped value is flat on this side of the naive clip objective, the gradient zeros out, and we don’t get to use this \((s,a)\) experience for gradient update even though this advantage is trying to force \(\pi'(a \mid s)\) up.
- If our advantage \(A < 0\) and our ratio \(r > 1 + \epsilon\) then our gradient zeros out once again, and we miss utilizing this \((s,a)\) experience for parameter update, even though the advantage is telling us to force \(\pi'(a\mid s)\) smaller.
Then our entire clipped objective adds a min term so that we only flattens the ratio on the side we care about!
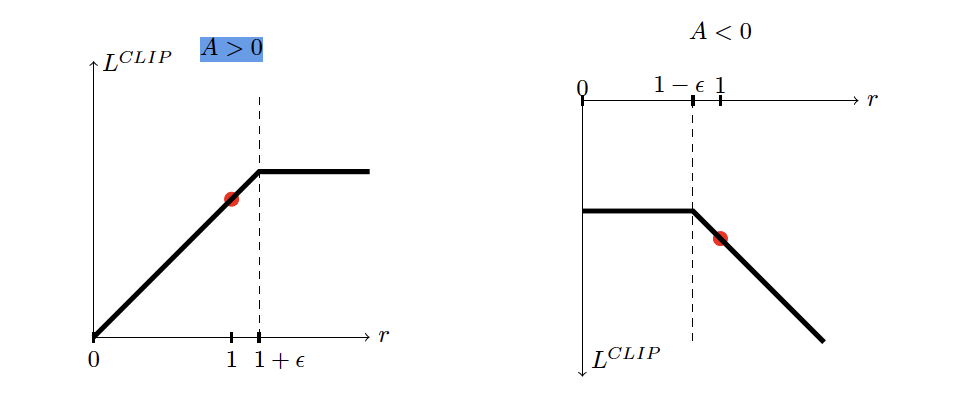
Asymmetric clipping
In reality we need to emphasize good actions when exploring for language models, meaning our clip term should be something like
This means that we want to make \(\epsilon_{+} < \epsilon_{-}\) so that we don’t clip for higher positive advantages that we would clip if we kept \(\epsilon_{-}\) fixed and had \(\epsilon_{+} = \epsilon_{-}\)!
TRPO - Trust-Region Policy Optimization
If we were to keep the KL-constraint in our objective instead of a soft ratio-clipping objective with PPO, then the formulation is different. This is called TRPO.
Our surrogate objective is now