Still in-progress writing
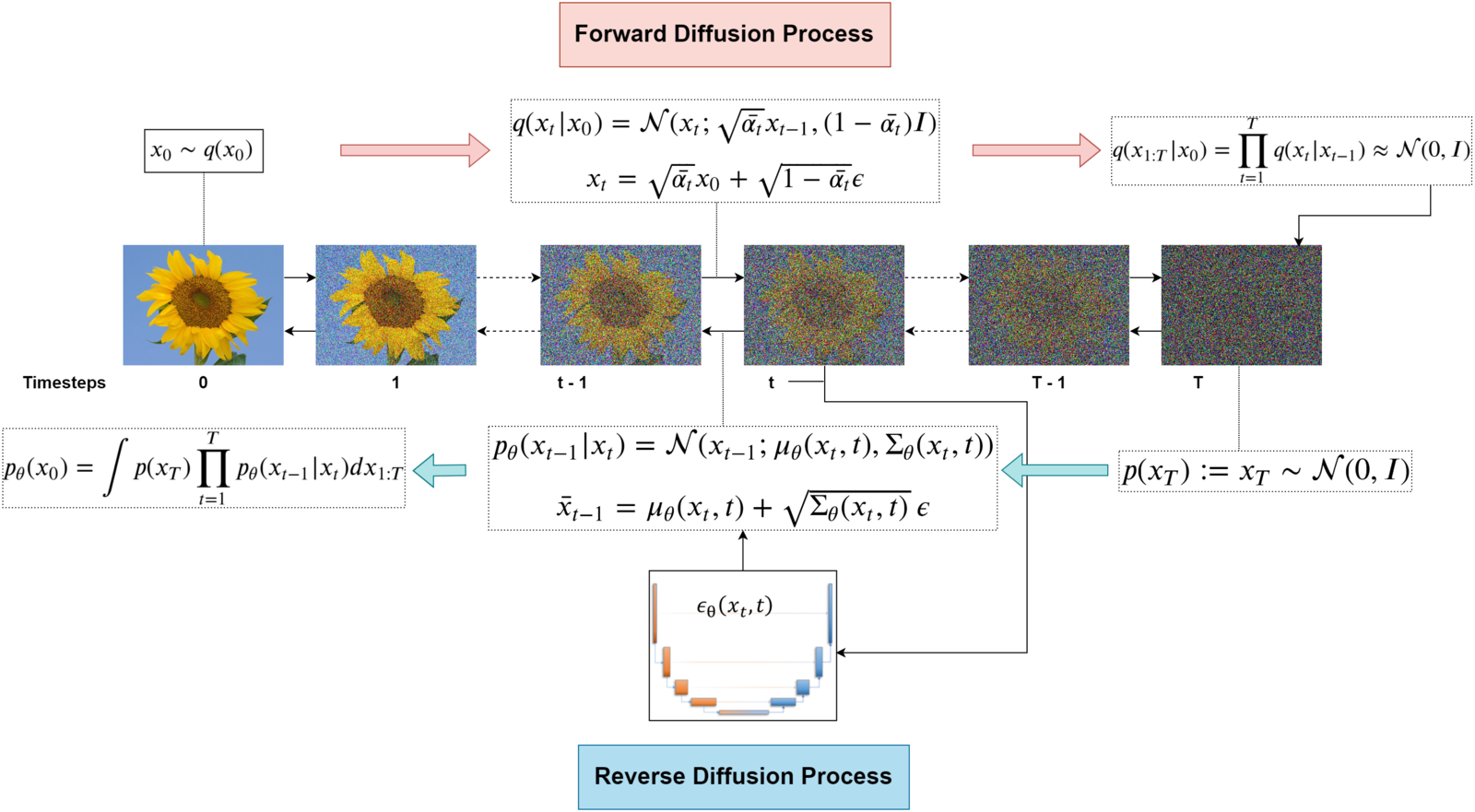
Forward Diffusion Process
Given an image data point \(x_0\) sampled from the image dataset distribution \(x_0 \sim q(x)\), let us gradually add Gaussian Noise in a series of \(T\) time steps, producing a sequence of noisy images (\(x_1, \dots x_T\)) where \(x_i\) is the image after the first \(i\) steps.
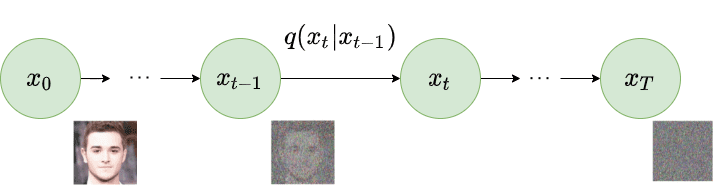
More formally this process can be described as the following: our image of \(d\) pixels can be flattened to a vector \(\in \mathbb{R}^d\) and for type-checking purposes can be normalized into pixel intensities \([-1, 1]\) (instead of \([0, 255]\)). Each transition step is a conditional probability distribution (\(q(x_t \mid x_{t-1}): \mathbb{R}^d \rightarrow \mathbb{R}^+\)), giving us the probability density for the image \(x_t\) given the previous time step’s \(x_{t-1}\). We call this process Markovian, because it satisfies the Markov Property: each step only relies on the previous step (more formally \(q(x_t \mid x_{0:t-1}) = q(x_t \mid x_{t-1})\))
To clarify some notation:
- Retrieving image \(x_t\) means retrieving from a Gaussian distribution denoted by \(\mathcal{N}(\text{mean}, \text{variance})\)
- Mean: \(\mu_t = \sqrt{1 - \beta_t} x_{t-1}\) of each pixel
- Covariance: \(\Sigma_t = \beta_t I\) (where \(I = \mathbb{R}^{d \times d}\) is the identity matrix)
- What this means is that each individual pixel (with variance at \(\Sigma_{p,p} = \beta_{t}\)) is independently distributed of each other since off-diagonal entries \(\Sigma_{p,q} = 0\).
- Using the reparameterization trick from VAEs, this means \(x = \mu + \sigma \odot \epsilon,\ \epsilon \sim \mathcal{N}(0, I),\ (\epsilon \in \mathbb{R}^d)\)
\(\beta_t \in [0, 1]\) is a constant given from our noise scheduler, \((\beta_1, \beta_2, \dots, \beta_T)\) specifying the variance (noise intensity) added each time step. One interesting question one might have is why include the \(\sqrt{1 - \beta_{t} }\) coefficient for mean. According to the reparameterization trick, since \(x_{t} = \sqrt{ 1-\beta_{t} } x_{t-1} + \sqrt{\beta_{t}} \epsilon\), and because \(x_{t-1}\) and \(\epsilon\) are sampled from independent gaussians we can state
Since we normalized our image to \([-1, 1]\), \(var(x_0) \leq 1\) , so then \(\forall t,\ var(x_{t}) \leq 1\). Apparently, this is called “variance preserving”. If our input \(var(x_0) \approx 1\), then \(var(x_t) \approx 1\) as well. The point is the variance is constant through the entire forward process!
Variance/Noise Schedule
Originally, the authors of DDPM utilizes a linear schedule.

Simplified Sampling Form
The joint distribution of the entire trajectory of \(T\) time steps, the product of all \(T\) different PDF —
— can be expressed a simpler closed form expression if we define a additional variables
- \(\alpha_t = 1-\beta_t,\quad t=1,\dots,T\) defining “fraction” of the previous step’s signal retained
- \(\bar\alpha_t = \prod_{s=1}^t \alpha_{s}\) denoting the fraction of the original image left after \(t\) time steps.
- \(\epsilon_0, \dots, \epsilon_{t-1} \sim \mathcal{N}(0, I),\ \epsilon_i \in \mathbb{R}^d\) is the gaussian noise added at each time step and induct on \(t\) or \(x_t\):
The key combined variance step is as follows: Since \(\epsilon_{t-2}\) and \(\epsilon_{t-1}\) are sampled independently, the linear combination of independent Gaussians stays Gaussian, and yields a merged standard deviation as follows
which allows us to replace \(\epsilon',\ \epsilon_{t-1}\) as sampling from a shared \(\epsilon \sim \mathcal{N}(0, I)\) Thus we can write
and thus produce a sample
As \(T \rightarrow \infty\), then we should have reached an isotropic Gaussian distribution, one where \(x_T \sim \mathcal{N}(0,I)\) follows a perfect gaussian distribution of mean \(0\). Note that is because \(\bar{\alpha}_{t} \rightarrow 0\) !
This is advantageous, because we all already know how to sample gaussian noise, so figuring out how to reverse the gaussian noise in the reverse diffusion process allows us to generate random images!
Reverse Diffusion Process
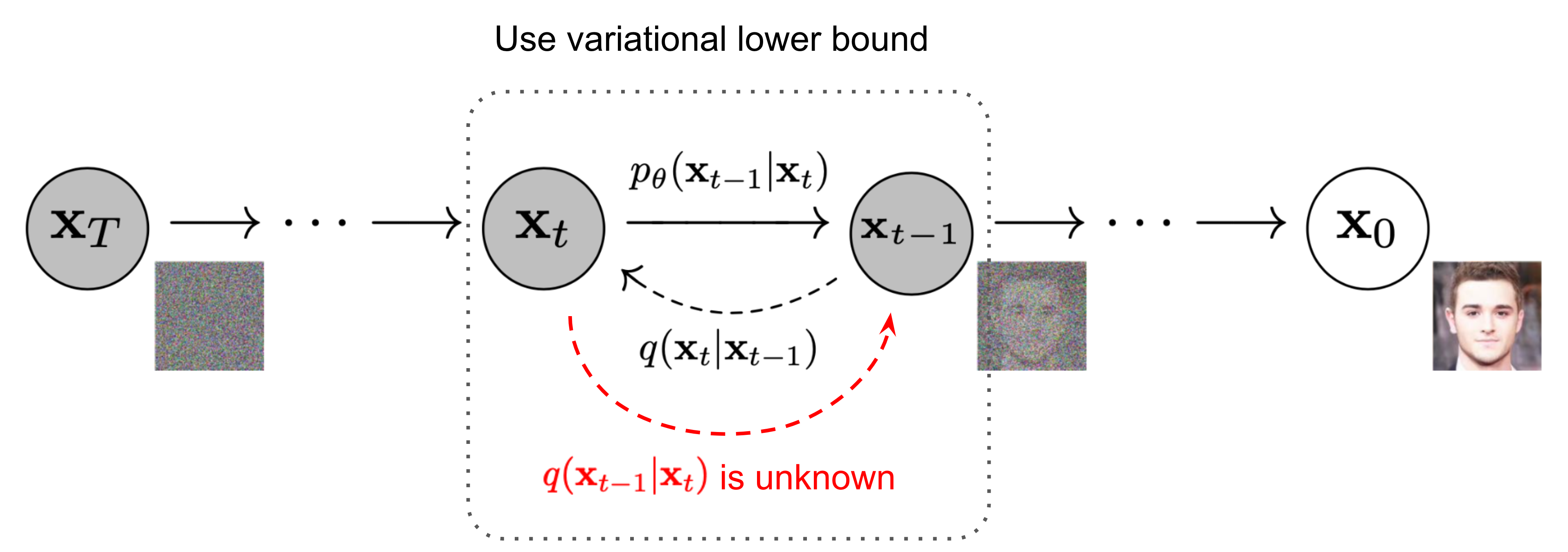
We want to learn the reverse distribution \(q(x_{t-1} \mid x_t)\) to acquire some new images in our dataset \(x_0\) by learning a deep learning model by \(p_{\theta}\) where we learn some estimate mean and variance through parameters \(\theta\):
One specific path we may take from \(x_T \rightarrow x_0\) is represented by
But the PDF of the entire reverse diffusion process is an “integral” over all the possible pathways we can take to reach \(x_0\).